- 搜索

快科技3月26日音书,谷歌探究院推出全新AI内存压缩时间TurboQuant,精确破解AI推理的内存瓶颈。
该时间可在不亏欠精度的前提下,将空话语模子缓存内存占用至少缩减6倍,推理速率最高升迁8倍。

AI模子动手时有一种“职责内存”,即KV缓存(Key-Value Cache)。每当模子处治信息、生成回当令,KV缓存便会赶快彭胀,且险峻文窗口越长,缓存占用的内存越大。
这已成为制约AI系统效用与资本的中枢瓶颈,并非模子不够智能,而是动手时的内存难以撑握。
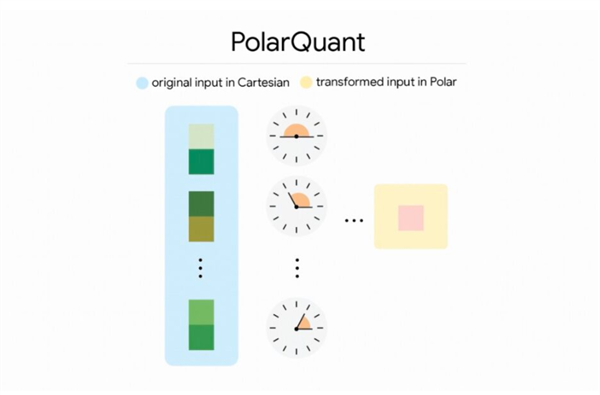
TurboQuant选拔向量量化的要津对缓存进行压缩,使AI在占用更少内存的同期记取更多信息,且保握准确性。收场这一效果的弱点在于两项时间:名为PolarQuant的量化要津,以及名为QJL的检修与优化妙技。探究团队斟酌不才个月的ICLR 2026会议上认真发布干系恶果。
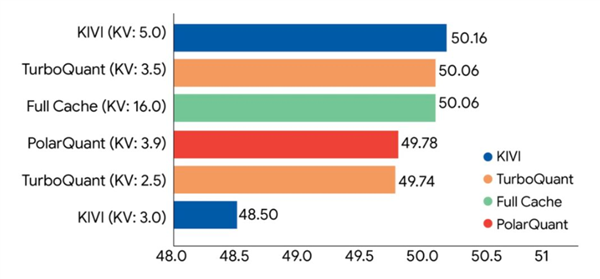
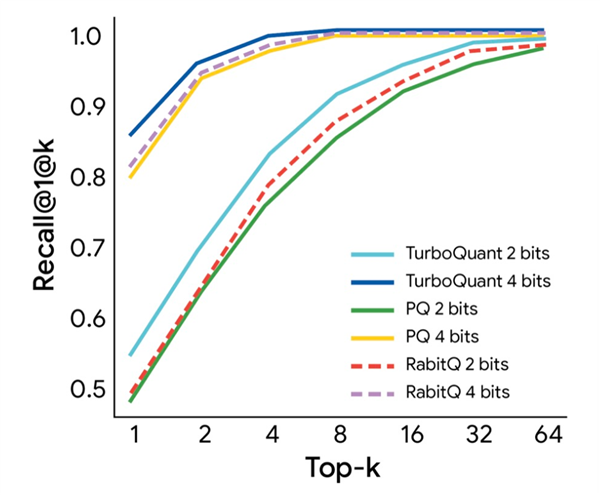
探究团队在Gemma和Mistral等开源大模子上进行了严格的基准测试。执行数据露出,TurboQuant无需任何预检修或微调,即可将键值缓存高效压缩至3比特,在“大海捞针”等长险峻文测试中收场零精度亏欠,内存占用降至蓝本的六分之一。
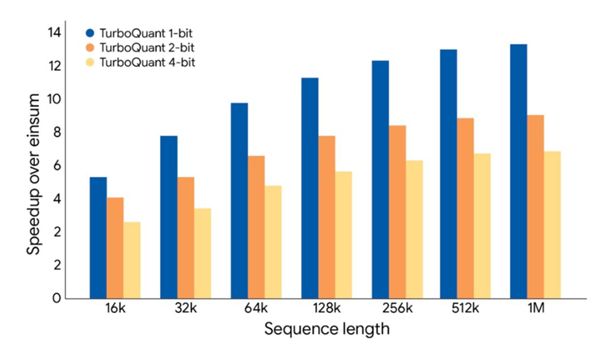
此外,在H100 GPU加快器上,4比特TurboQuant的动手速率较未量化的32比特基准升迁了高达8倍。